Table of Contents
1. Introduction
인간은 빠르고 정확한 시각 시스템 덕분에 여러 복잡한 일들을 할 수 있습니다. 비슷하게, 빠르고 정확한 Object Detection 알고리즘이 있다면 자율주행 등 복잡한 task들을 컴퓨터가 직접 할 수 있게 도와줄 것입니다.
현재 R-CNN, Faster R-CNN 같은 계열의 알고리즘은 Region Proposals이라는 매우 느린 과정이 필요하기 때문에 최대 5fps의 성능을 보여줍니다. 이는 복잡하고, 인간의 시각에 비하면 매우 느립니다.
반면에 이 글에서 소개하는 YOLO(You Only Look Once) 모델의 같은 경우, detection 과정을 하나의 regression 문제로 생각해 end-to-end 모델을 구성하게 해 줍니다. 이 덕분에 YOLO 모델은 45fps라는 빠른 속도로 Detection을 수행할 수 있습니다.
2. Unified Detection
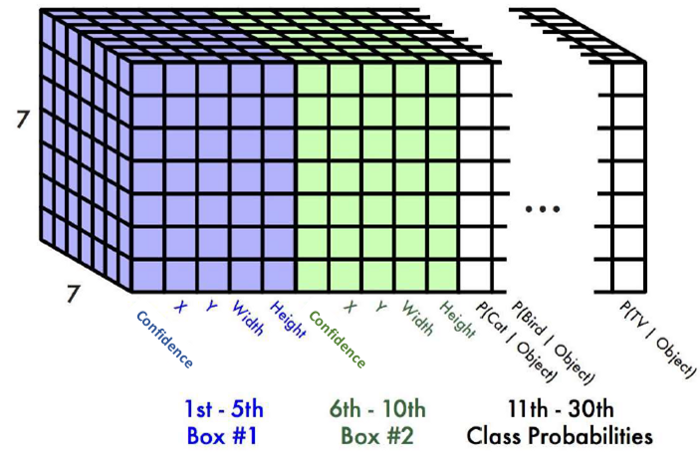
먼저, Input이 들어오면 모델은 이미지를 \(S * S (S=7)\) 개의 grid cell로 나눕니다. 이제 이 \(S^2\) 개의 cell에 대해 object인지 아닌지 detecting 하게 됩니다.
각각의 grid cell은 \(B (B=2)\)개의 Bounding box와 각각의 box에 대해 \(confidence\)를 예측하게 됩니다.
Bounding Box
\(B\) 개의 Bounding box는 각각 5개의 값을 예측하게 되는데, 4개는 Bounding box의 크기와 위치를 예측하는 \((x,y,w,h)\) 이고 하나는 Boundig box가 object를 담고 있는지 예측하는 \(confidence\) 값입니다. 만약에 bounding box안에 object가 없다면 이 값은 0이 될 것이고, object가 존재한다면 1에 가까워 질 것입니다.
여기서 \((x,y)\)는 Bounding Box의 중심이 grid cell의 bound로부터 얼마나 떨어져있는지 나타내는 상댓값이고, \((w,h)\)는 Bounding Box의 크기를 Input 이미지 크기와 상대적으로 나타낸 값입니다.
Confidence
Confidence는 다음과 같이 정의됩니다.
\(confidence = Pr(Object) * IOU\)
IOU는 예측한 Bounding box와 원래의 box가 얼마나 일치하는지 0과 1사이로 나타낸 값입니다. 예측한 bounding box 를 \(pred\), 원래의 box를 \(truth\)라하면 \(IOU = \frac{truth\cap pred}{truth\cup pred}\) 로 정의할 수 있습니다.
Conditional class probability
또한 각 grid celld은 C개의 Conditional class probability인 \(Pr(Class_{i}|Object)\)를 예측하게 됩니다. 이 값은 grid cell마다 한 번씩만 예측하는 것으로 Bounding box의 숫자와는 관련이 없습니다.
이렇게 구성된 YOLO의 output은 다음과 같습니다. 논문에서는 PASCAL VOC 데이터셋을 사용하여 \(S=7, B=2, C=20\)을 사용해 다음과 같은 output을 얻었습니다.
3. Network Architecture
 24개의 Conv Layer 에 2개의 FC Layer를 이어붙여 만들었고, GoogLeNet과 같이 1x1의 Conv Layer를 사용하였습니다.
24개의 Conv Layer 에 2개의 FC Layer를 이어붙여 만들었고, GoogLeNet과 같이 1x1의 Conv Layer를 사용하였습니다.
그리고 training 과정에서,
1) ImageNet을이용해 20개의 Conv Layer를 pre-train 후 4개의 Conv, 2개의 FC Layer 추가 2) Input 이미지의 해상도를 448x448로 증가시킴 3) Activation 함수로 Leaky ReLU 사용
Loss Function
YOLO 모델에서는 optimize하기 비교적 쉬운 SSE(Sum-Squared Error)를 사용하였습니다. 하지만 대부분의 grid cell에는 object가 없으므로 confidence 값을 0으로 만들수 있습니다. 이런 loss 함수는 네트워크를 불안정하게 만듭니다.
이를 해결하기 위해, Object를 포함한