AlexNet(2012) : ImageNet Classification With Deep Convolutional Neural Network
01 Jul 2019
Reading time ~3 minutes
1. Introduction
현재의 대부분 Object 인식은 머신러닝 기법을 사용한다. 간단한 인식은 작은 datasets 으로도 좋은 결과(accuracy)를 얻을 수 있다. 예를 들어 현재 MNIST digit-recognition task의 가장 좋은 에러율은 <0.3%로 사람과 비슷하다 그러나 현실에서의 object 인식 과정은 많은 variablity가 존재하므로 더 큰 datasets으로 학습을 진행해야 한다. AlexNet의 경우 22,000개의 label을 가진 15 million 이상의 datasets인 ImageNet datasets을 사용하였다. 또한 AlexNet은 학습에서 두개의 GTX 580 3GB GPUs를 사용하여 진행하였다.
2. Datasets
ImageNet dataset을 사용하였다. Input을 일정하게 하고자 모든 이미지들을 256 X 256로 down-sampled 하고, 평균을 빼서 zero-centered 된 이미지를 사용하였다.
3. Architectures
3.1 ReLU Nonlinearlity
saturation을 피하고 빠른 수렴속도를 위해 Sigmoid나 tanh 대신 ReLU를 사용하였다.
3.2 Training on Multiple GPUs
3.3 Local Response Normalization

ReLU를 사용하면 Input을 normalization 하지 않아도 된다. 그러나 generalization을 위해 ( ReLU 값이 한없이 커질수 있어서) LRN을 사용하였다. 이를 통해 주변 kernal에 비해 너무 큰 값 등을 보정한다. 이 정규화 기법은 “adjacnet”한 n개의 kernal을 이용하여 정규화 하는 것이다. 여기서 k, n, α, β는 hyperparameter로 AlexNet에서는 k = 2, n = 5, α = 10^−4, β = 0.75을 사용하였다.
이러한 방식을 통해 AlexNet은 top-1 와 top-5 에러를 각각 1.4%와 1.2% 낮출 수 있었다.
3.4 Overlapping Pooling
Stride와 필터의 크기가 같은 일반적인 Pooling Layer와 달리 s(stride) = 2 , z(size) = 3으로 하는 Overlapping Pooling을 사용하였다. 이를 통해 기존(s=z=2)보다 top-1 , top-5 error을 0.4%, 0.3% 감소시켰다.
4. Reducing Overfitting
계산량이 매우 적은 두가지의 Data Augmentation 기법들을 사용하였다. 이를 통해 1) CPU에서 Image 생성, 2) GPU에서 이전 batch training 을 동시에 진행하였다.
4.1 Data Augmentation
- Image 추출과 Reflection
원본 data로 부터 224*224의 Random patches 추출 하고 horizontal reflection을 진행하였다. 이를 통해 기존의 2048배의 Data를 얻을 수 있다.
test time에서는 5개의 patch(4개의 코너와 중앙)과 reflection으로 총 10개의 patch를 얻고, 10개의 예측값의 평균을 사용하였다. - PCA on the RGB set
4.2 Dropout
p=0.5로 첫번째와 두번째의 FC Layer에 dropout을 사용하였다.
5. Details of Learning / Implementation
5.1 Architecture
총 5개의 CONV Layer, 3개의 FC Layer를 사용하였다. 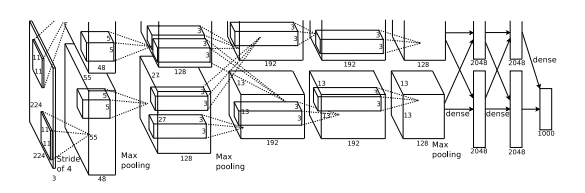 #0 Input : 227*227*3의 Input
#0 Input : 227*227*3의 Input
#1 CONV : 96개의 11*11 Filter 사용 (padding=0,stride=4)
#1 CONV : Output 55*55*96 , Parameter = 34848
#1 Pooling, LRN : s=2,z=3의 pooling 사용
#1 Pooling, LRN : Output 27*27*96
#2 CONV : 256개의 5*5 Filter 사용 (padding=2, stride=1)
#2 CONV : Output 27*27*256 , Parameter = 614400
#2 Pooling, LRN : Output 13*13*256
#3 CONV : 384개의 3*3 Filter 사용 (padding=1, stride=1)
#3 CONV : Output 13*13*384 , Parameter = 884736
#4 CONV : 384개의 3*3 Filter 사용 (padding=1, stride=1)
#4 CONV : Output 13*13*384, Parameter = 1327104
#5 CONV : 256개의 3*3 Filter 사용 (padding=1, stride=1)
#5 CONV : Output 13*13*256, Parameter = 884736
#5 Pooling : Output 6*6*256
#6 FC1 : 4096의 FC Layer
#6 FC1 : Output 4096, Parameter = 37748736
#7 FC2 : 4096의 FC Layer
#7 FC2 : Output 4096, Parameter = 16777216
#8 FC3 : 1000의 FC Layer
#8 FC3 : Output 1000, Parameter = 4096000
5.2 Details
Size가 128인 Batch, SGD, 0.9의 momentum, 0.0005의 weight decay를 사용하였다.
또한 각 layer의 weight들을 N(0,0.01)의 분포로 초기화 하였다. bias의 경우 #1,3,4 CONV, FC는 1로, 나머지는 0으로 초기화하였다.
그리고 모든 Layer의 learning rate는 0.01로 초기화하고, validation error가 줄어드는게 멈추면 10으로 나누어 사용하였다.
5.3 Implementation
ImageNet 데이터셋이 너무 큰 관계로.. Cat and Dog 데이터셋(https://www.kaggle.com/tongpython/cat-and-dog/)을 사용하였다 . 또한 구현에 있어 Finetune AlexNet with Tensorflow(https://github.com/kratzert/finetune_alexnet_with_tensorflow)를 참고하였다. 또한 Google Colab을 이용하였다.